
TIBCO Scribe® Online Connector For Amazon S3
Use the TIBCO Scribe® Online Connector for Amazon S3 to extract data from another datastore through an existing TIBCO Scribe® Online Connection and save that data as a CSV file, a JSON file, or a Amazon Redshift JSON file in a folder inside an Amazon S3 bucket. That file can then be used as a data source by any Connector that can parse the files based on the file type. For example, the TIBCO Scribe® Online Connector For Amazon Redshift can parse a Amazon Redshift JSON file stored in an Amazon S3 bucket.
Connector Specifications
| Supported | |
|---|---|
|
Agent Types |
|
| On Premise | X |
| Cloud | X |
|
Replication Services |
|
| Source | |
| Target | |
|
Integration Services |
|
| Source | X |
| Target | X |
|
Migration Services |
|
| Source | X |
| Target | X |
|
Maps |
|
| Integration | X |
| Request-Reply | |
| Message | |
Note: This Connector is available from the TIBCO Scribe® Online Marketplace. See Marketplace TIBCO Scribe® Certified Connectors for more information.
Supported Entities
The Amazon S3 Connector supports the following entities. Click a linked entity name for additional information when using that entity in TIBCO Scribe® Online.
Standard Operations
| Entity | Query | Create | Update | Delete | Upsert |
|---|---|---|---|---|---|
|
X |
X |
|
X |
|
Special Operations
| Entity | Operations |
|---|---|
|
-Copy |
Setup Considerations
To access Objects in an Amazon S3 Bucket you must have been granted the following permissions for read-write access to the Bucket:
- s3:ListBucket
- s3:PutObject
- s3:GetObject
- s3:DeleteObject
Contact your Amazon AWS Administrator for assistance in configuring these permissions.
Selecting An Agent Type For Amazon S3
Refer to TIBCO Scribe® Online Agents for information on available Agent types and how to select the best Agent for your Solution.
Connecting To Amazon S3
Note: Best practice is to create Connections with credentials that limit permissions in the target system, following the principle of least privilege. Using Administrator level credentials in a Connection provides Administrator level access to the target system for TIBCO Scribe® Online users. Depending on the entities supported, a TIBCO Scribe® Online user could alter user accounts in the target system.
Note: Connecting to Amazon S3 buckets with mult-factor authentication enabled is not supported.
- Select More > Connections from the menu.
- From the Connections page select Add
 to open the Add a New Connection dialog.
to open the Add a New Connection dialog. - Select the Connector from
the drop-down list in the Connection Type field, and then enter the following information for this Connection:
- Name — This can be any meaningful name, up to 25 characters.
- Alias — An alias for this Connection name. The alias is generated from the Connection name, and can be up to 25 characters. The Connection alias can include letters, numbers, and underscores. Spaces and special characters are not accepted. You can change the alias. For more information, see Connection Alias.
- Associate With Connection — TIBCO Scribe® Online Connection for the datastore from which you are extracting data.
- AWS Access Key ID — Your Amazon web services access key.
- AWS Secret Access Key — Your Amazon web services secret access key.
- AWS Storage Region — Your Amazon storage region key.
- S3 Bucket Name — Name of an Amazon web services bucket associated with your AWS account.
- Folder — Folder in Amazon S3 where the extracted data should be stored. If this folder does not already exist, it is created the first time a Solution using this Connection is executed.
- Object Prefix — User-defined prefix added to the name of the Object created when the data is extracted. Object names are based on the entity being extracted, such as Account or Contact. Use the prefix to ensure that entity names are unique in situations where data from multiple Amazon S3 Connections is being stored in the same S3 Bucket and Folder. For example, if you are extracting data form both Salesforce and Microsoft Dynamics 365, both have an Account entity and would generate an Object named Account.
- Message Format — Choose CSV, standard JSON format, or Redshift compliant JSON. Only use Redshift if you are using the Amazon Redshift Connector to read the JSON files.
- Overwrite Data On Create — Indicates whether or not to overwrite an existing Object when a Solution using this Connection is executed more than once. True overwrites the existing Object. False appends records to the existing Object. Default is true.
Note: Appending records to an existing Object can result in duplicate records.
- Select Test to ensure that the Agent can access your Amazon S3 Bucket. Be sure to test the Connection against all Agents that use this Connection. See Testing Connections.
- Select OK/Save to save the Connection.
Metadata Notes
Resetting Metadata
If you make schema changes to a data source, you must reset the metadata for that datastore. When TIBCO Scribe® Online resets the metadata, it drops and recreates the schema for the Connection's datastore.
The Connector for Amazon S3 extracts data using existing TIBCO Scribe® Online Connections to other applications and stores that data in its own datastore. In this case, if you need to refresh the metadata, you must first refresh the third-party Connection, and then the Amazon S3 Connection. For example, if you are using the Amazon S3 Connection to extract data from Salesforce, first reset metadata for the TIBCO Scribe® Online Salesforce Connection and then reset metadata for the Amazon S3 Connection. See Resetting Metadata.
Metadata Files
When a Solution using an Amazon S3 Connection executes, two Objects or files are generated for the selected entity and stored in your S3 Bucket in the Folder configured on the Amazon S3 Connection dialog. For example, if the Solution extracts Contact data from Salesforce through the Amazon S3 Connection, the following two files are generated:
- contact.metadata — Contains the schema for the selected entity including field names, field lengths, and data types.
- contact.data.json.1490555852.0633 — Entity data in a JSON format.
If you entered an Object Prefix on the Amazon S3 Connection dialog, that prefix is pre-pended to the name of the Object. For example, if the configured Object Prefix is SF, then the Object names would be SFcontact.data.json.1490555852.0633 and SFcontact.metadata.
Amazon S3 Connector As IS Source / Target
The process for using the Connector for Amazon S3 is slightly different than most Connectors because the Amazon S3 Connector is retrieving data from a third-party Connection and storing it in Amazon S3 as a set of objects in a CSV, JSON, or Amazon Redshift compliant JSON format. The object set consists of a metadata file and one or more data files.
When using Amazon S3 as a source the Connector represents an entire object set as a single source entity. For example, a metadata file and several data files associated with Contact information are represented as a single source entity named Contact.
Review the example processes below to learn how to use the Connector for Amazon S3.
Example: Moving Data Into Amazon S3
For the purposes of this example, assume that you want to move Salesforce Contacts to your Amazon S3 Bucket, and have that data retrieved by another Connection, such as Amazon Redshift.
- Determine which third-party data you want to move to your Amazon S3 Bucket so that it is converted to either CSV, JSON, or Redshift compliant JSON. In this case it is Salesforce.
- Configure a TIBCO Scribe® Online Connection to Salesforce.
- Configure a TIBCO Scribe® Online Connection to Amazon S3 with the following settings:
- Associate With Connection set to your Salesforce Connection
- Folder named MyFiles
- Object Prefix set to SF
- Configure a Solution and Map as follows:
- Add both a Salesforce and an Amazon S3 Connection to the Map.
- Add and configure a Query Block from the Salesforce Connection to retrieve Salesforce Contacts. Here Salesforce is the data Source.
- Add a For Each Result Block.
- Inside the For Each Result Block, add a Create Block from the Amazon S3 Connection. Here Amazon S3 is the Target.
The Create Block uses the Associate With Connection field setting for Salesforce configured in the Amazon S3 Connection to get the metadata schema from Salesforce. When you are configuring the Field Mappings for the Create Block, the schema provides the field names for the Amazon S3 Target side metadata file. Amazon S3 is just a container for the resulting JSON or CSV file object set and has no concept of the inbound data structure.
- Save the Map and Solution.
- Run the Solution to store the Salesforce data in your Amazon S3 Bucket.
Example: Moving Data From Amazon S3 To Another Datastore
Continuing with the example above, the next step is to move the data in the files in Amazon S3 to another system using a Connector that can parse those files, such as Amazon Redshift. For Amazon Redshift the files must be Redshift compliant JSON.
- Configure a TIBCO Scribe® Online Connection to Amazon Redshift.
- Configure a Solution and Map as follows:
- Add both an Amazon S3 and an Amazon Redshift Connection to the Map.
- Add a Query Block from the Amazon S3 Connection and select ObjectSets as your Entity. If you have more than one set of Redshift compliant JSON files in your Amazon S3 Bucket, use ObjectKey as a filter and set it to is like with a value of the entity name, such as contact.
Note: For regular JSON and CSV files, the Query Block displays an entity name, such as Contact or Account.
- Use the Preview tab on the Query Block to view your data and make sure you are retrieving the correct files. The ObjectKey displayed in the Preview tab displays FolderName/ObjectPrefixEntityName, for example, MyFiles/SFcontact.
- Add a For Each Result Block.
- Inside the For Each Result Block add a Copy Block from the Amazon Redshift Connection.
- In the Copy Block the default entity is AmazonS3Storage.
- On the Fields Tab map the Source Fields to the Amazon Redshift Fields as shown below:

The TableName field is required but does not have to match the Object Prefix and entity name in the Source data. You can modify it to anything you need. This is particularly important in a case where the source entity name contains special characters that could cause a problem in the target datastore.
- Save the Map and Solution
- Run the Solution to move the data into Amazon Redshift.
When the Solution runs, the Amazon Redshift Connector builds a table in Amazon Redshift based on the metadata schema from the Salesforce Connection and populates that table with the data stored in the JSON file.
Notes On Standard Entities
ObjectSets
ObjectSets is a virtual entity created by the Connector for Amazon S3 to represent the data extracted from the Associated Connection configured in the Connection dialog.
- This entity contains the following two fields:
- BucketName — Name of the Amazon S3 Bucket where the data is stored.
- ObjectKey — Unique identifier for the Object from the third-party datastore stored in Amazon S3. Consists of the Folder and Object Prefix configured on the Amazon S3 Connection dialog, and the entity name of the original Source entity. For example, MyFiles/SFcontact, where MyFiles is the Folder, SF is the Object Prefix, and contact is the entity.
- Filter, Match Criteria, Lookup —
- Filtering is supported only on the entity name contained in the ObjectKey field. For example, if the entire ObjectKey is MyFiles/SFcontact, the filter field is ObjectKey and the filter value is contact.
- Only the is like operator is supported.
ObjectSetTransfer
ObjectSetTransfer is a virtual entity created by the Connector for Amazon S3 to represent the data to be copied from one Amazon S3 area to another.
Notes On Operations
Query
Returns all ObjectSets based on the S3 Bucket, Folder, and Object Prefix configured in the Amazon S3 Connection dialog. The entity name for the Query is always ObjectSets.
For JSON and CSV files, Query returns each element as an entity, such as Account or Contact. The contents of the entity are visible in the Query Block Preview tab.
Create
When using the Create operation, the entity name is the base name of the object set that will be created, excluding prefixes and folders, and is drawn from the entity being queried from the third-party datastore. For example, if you Query Salesforce Contacts and then use the Amazon S3 Create operation to create an Object in Amazon S3 containing the Salesforce Contacts, the entity name displayed in the Create Block is Contacts, not ObjectSets.
Enabling Batch Processing is recommended when using the Create operation to store third-party data in an Amazon S3 Bucket. If Batch Processing is not enabled, each record is stored in a separate Object. If Batch Processing is enabled, each batch of records is stored in a separate Object. For example, if Batch Processing is set to 2000 records, each Object will contain a maximum of 2000 records. This improves performance and requires fewer API calls. See Batch Processing.

Delete
ObjectSets can be deleted by matching either the file name or the Object Prefix configured in the Connection dialog. Filtering by more than one field is not supported.
Note:
Delete only removes entire files not individual records within a file.
The Delete operation is not limited to the file type selected in the Message Format field on the Connection dialog. All files are deleted.
Copy
Use Copy to move ObjectSets from one Amazon S3 area or bucket to another without having to generate the files again.
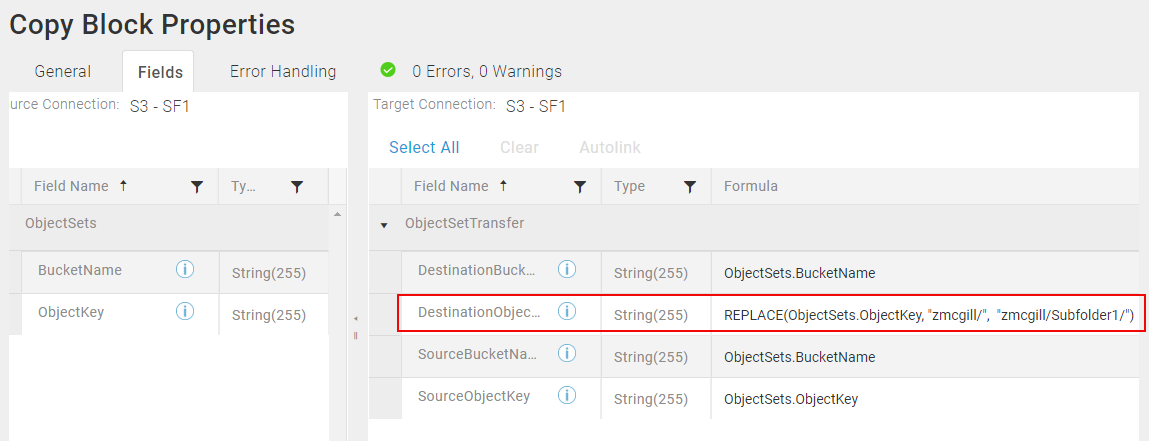
Copy ObjectSets To A New Folder In The Same Bucket
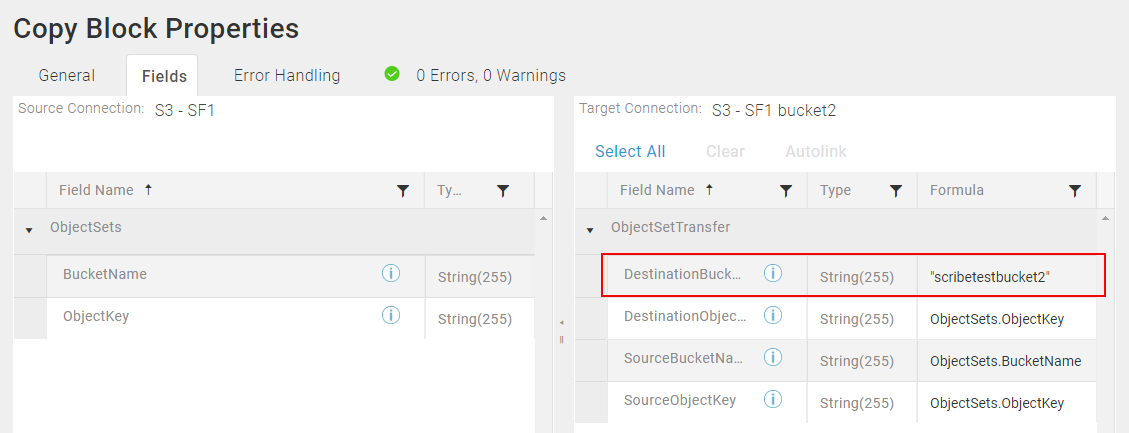
Copy ObjectSets To A Different Bucket
When configuring the Fields tab on the Copy Block keep in mind the following:
- The Amazon S3 bucket name and folder configured on the Amazon S3 Connection dialog do not affect the destination bucket name and folder.
- If you are copying ObjectSets within the same bucket, you cannot simply map the Source ObjectKey directly to the DestinationObjectKey. You must use a formula to modify the DestinationObjectKey or an error is generated indicating that the ObjectKey already exists. For example, if the Source ObjectKey is MyFiles/SFcontact, where MyFiles is the Folder, SF is the Object Prefix, and contact is the entity, you could use the REPLACE function in the DestinationObjectKey to add a sub-folder by modifying the ObjectKey as follows:
REPLACE(ObjectSets.ObjectKey, "MyFiles/", "MyFiles/Folder2/")
- If you are copying to a different bucket, provide the name of the bucket in the DestinationBucketName field.
TIBCO Scribe® Online API Considerations
To create connections with the TIBCO Scribe® Online API, the Amazon S3 Connector requires the following information:
|
Connector Name |
Amazon S3 |
|
Connector ID |
0FAF1B93-F387-4B65-BDAE-38C793BA72D3 |
TIBCO Scribe® Online Connection Properties
In addition, this Connector uses the Connection properties shown in the following table.
Note: Connection property names are case-sensitive.
| Name | Data Type | Required | Secured | Usage |
|---|---|---|---|---|
|
AssociatedConnectionId |
String |
Yes |
No |
|
|
AwsAccessKeyId |
String |
Yes |
No |
|
|
AwsSecretAccessKey |
String |
Yes |
Yes |
|
|
AwsStorageRegionKey |
String |
Yes |
No |
|
|
BucketName |
String |
Yes |
No |
|
|
Folder |
String |
Yes |
No |
|
|
UserDefinedString |
String |
Yes |
No |
|
|
IsRedshift |
String |
Yes |
No |
This field contains the file type being generated and corresponds to the Message Format field on the Connection UI. Options are: • Redshift • Json • Csv |
|
AlwaysOverwrite |
String |
Yes |
No |
|
License Agreement
The TIBCO Scribe® Online End User License Agreement for the Amazon S3 Connector describes TIBCO and your legal obligations and requirements. TIBCO suggests that you read the End User License Agreement.
More Information
For additional information on this Connector, refer to the Knowledge Base and Discussions in the TIBCO Community.